kafka paper - the first paper i read and tried to implement it
As the blog title says this is the first paper i actually tried to read properly and implement. At first it felt confusing and heavy but as i kept going things started to make more sense, especially why Kafka is designed the way it is. So instead of just reading it i decided to build a simplified version of it from scratch.
This project took me around a month and i can say this is my peak work till now. I didn’t rush it, i tried to go layer by layer and understand what i am building instead of just coding things blindly. This is not a production-ready system, it’s a learning implementation.
Also just to set expectations, this is not a fully distributed Kafka implementation. It’s somewhere in between and this is the current state of what I have built:
- Storage is only partition-based, not replicated. Each partition lives on exactly one broker and is stored locally on disk.
- There are multiple brokers, and partitions are assigned to brokers. A coordinator service decides which broker owns which partition and clients route requests to the correct broker.
- Producer side is implemented, it can choose partitions using round-robin, key-based hashing, or explicit partition and then sends data to the broker.
- Consumer side is also implemented, it polls data from brokers and works with consumer groups and committed offsets.
- The system is mostly synchronous. Producer calls broker directly, broker writes to storage directly, and consumer polls directly. No real async processing or background workers yet.
- Only small async-like behavior is long-polling in fetch using wait/notify, but it’s not a fully async or non-blocking system.
What is still missing compared to real Kafka:
- replication across brokers
- leader/follower or any consensus
- actual network communication between brokers
- persistent distributed metadata
- async processing / non-blocking APIs
So overall, this is a broker-based, partitioned, Kafka-like system with multiple brokers and routing, but not fully distributed and not asynchronous yet.
Before starting the implementation i had written a small article where i broke down the design and architecture of Kafka in simple words. You can read it here. . While implementing i realised there were a few gaps and wrong assumptions in that, so i’ll point them out in this blog as we go.
In this blog i’ll walk through how i built everything step by step, starting from a very basic storage engine and then slowly adding more pieces on top of it. Each step basically came from something breaking or not scaling in the previous one, and that’s what made the whole process interesting. If you just want to see the code
Github repo - https://github.com/akansha204/kofta
Paper link - https://notes.stephenholiday.com/Kafka.pdf
What I initially planned to do?
I wanted to keep the implmentation limited and minimal - a single-broker Kafka implemenation, was not even thinking of making it distributed. I started of with a core log segment–based storage engine with disk reads and writes of Messages added the serialisation and deserialisation of messages with sequential offsets assigned per partition.
1import java.io.*;
2
3public class LogSegment {
4 private RandomAccessFile file;
5 private long currOffset;
6 public LogSegment(String path) throws IOException {
7 this.file = new RandomAccessFile(path, "rw");
8 this.currOffset = 0;
9 }
10 public synchronized long append(String message) throws IOException {
11 long newOffset = currOffset + 1;
12 currOffset = newOffset;
13
14 Message msg = new Message(
15 newOffset,
16 System.currentTimeMillis(),
17 message.getBytes()
18 );
19
20 byte[] data = serialize(msg);
21
22 long fileOffset = file.length();
23 file.seek(fileOffset);
24 file.write(data);
25
26 return newOffset;
27 }
28
29 public Message read(long fileOffset) throws IOException {
30 file.seek(fileOffset);
31
32 int length = file.readInt();
33
34 byte[] buffer = new byte[4 + length];
35 file.seek(fileOffset);
36 file.readFully(buffer);
37
38 return deserialize(buffer);
39 }
40
41 private byte[] serialize(Message msg) throws IOException {
42 ByteArrayOutputStream baos = new ByteArrayOutputStream(); //writes to in-memory byte[] buffer
43 DataOutputStream dos = new DataOutputStream(baos);
44
45 int totalLength = 8 + 8 + msg.payload.length;
46
47 dos.writeInt(totalLength);
48 dos.writeLong(msg.offset);
49 dos.writeLong(msg.timestamp);
50 dos.write(msg.payload);
51
52 return baos.toByteArray();
53 }
54
55 private Message deserialize(byte[] data) throws IOException {
56 ByteArrayInputStream bais = new ByteArrayInputStream(data); //reads from in-memory byte[] buffer
57 DataInputStream dis = new DataInputStream(bais);
58
59 int length = dis.readInt();
60 long offset = dis.readLong();
61 long timestamp = dis.readLong();
62
63 byte[] payload = new byte[length - 16];
64 dis.readFully(payload);
65
66 return new Message(offset, timestamp, payload);
67 }
68
69}The above code was the main core logStorage engine, followed by Message class.
1public class Message {
2 public final long offset;
3 public final long timestamp;
4 public final byte[] payload;
5
6 public Message(long offset, long timestamp, byte[] payload) {
7 this.offset = offset;
8 this.timestamp = timestamp;
9 this.payload = payload;
10 }
11}Till now this was very simple storage log engine responsible to store partition logs as segments (append-only log chunks). At this point it was just a single segment per partition (no segment rolling yet) not even multi-partitioned yet. The flow till now looked like this -
1Producer -> LogSegment (append) -> File on Disk
2 |
3 Message with offset and timestamp
4 |
5 Binary format for persistence
6 |
7Consumer -> LogSegment (read) -> Message from DiskI am assuming you have read the small article that i wrote on it so you know what is offsets why its used in this design. If you havent offsets are monotonically increasing identifiers representing the position of a record within a partition. Serialization and deserialization are used for binary on-disk representation of records. Also in real Kafka, offsets are resolved to physical file positions using index files before reading from disk.
Now till this i was satisfied enough and this was all my initial storage implementation didnt even tried implementing Record batches, CRC validation, or log recovery mechanisms. I thought all of this would be hard to digest so i avoided them and i can say it was my biggest mistake. Why? cause later i had to implement them anyway and i kept going on forward by building Producers, Broker APIs, and Consumers on top of this simplified storage layer. The system started becoming tightly coupled and complex and i had to modify everything in storage engine to introduce record batches, CRC validation, and log recovery.
After this simple storage log engine i started with Producers first, No broker abstraction yet the Producer was directly writing to a Partition.
1public class Producer {
2 private Partition partition;
3 public Producer(Partition partition){
4 this.partition = partition;
5 }
6 public long send(String message) throws IOException {
7 return partition.append(message);
8 }
9}Similarly minimal Consumer class directly reading from a Partition (reading by offset which is internally mapped to file position).
1public class Consumer {
2 private Partition partition;
3 private long curroffset = 1;
4
5 public Consumer(Partition partition){
6 this.partition = partition;
7 }
8
9 public void poll(int maxMessages) throws Exception{
10 for(int i=0;i<maxMessages;i++){
11 try {
12 Message msg = partition.read(curroffset);
13 if (msg == null) break;
14
15 System.out.println("Consumed: " + new String(msg.payload));
16 curroffset++;
17 } catch (RuntimeException e) {
18 if (e.getMessage().equals("Offset not found")) {
19 System.out.println("No more messages to consume.");
20 break;
21 } else {
22 throw e;
23 }
24 }
25 }
26 }
27}Everything worked fine till now but i was satisfied with this design. But it was too simple and not scalable. So started with adding a Broker layer between Producer and Consumer cause Kafka is built around brokers as the core server abstraction.
1public class Broker {
2 public Map<String, Partition> topics = new HashMap<>();
3 public void createTopic(String topicName) throws TopicAlreadyExistsException, IOException {
4 if (topics.containsKey(topicName)) {
5 throw new TopicAlreadyExistsException("Topic already exists");
6 }
7 topics.put(topicName, new Partition("../data/" + topicName));
8 }
9 public void send(String topicName, String message) throws TopicNotFoundException, IOException {
10 if (!topics.containsKey(topicName)) {
11 throw new TopicNotFoundException("Topic not found");
12 }
13 topics.get(topicName).append(message);
14 }
15 public List<Message> consume(String topic, long offset, long maxMessages) throws TopicNotFoundException, IOException {
16 if(!topics.containsKey(topic)){
17 throw new TopicNotFoundException("Topic not found");
18 }
19 List<Message> messages = new ArrayList<>();
20 for(int i=0;i<maxMessages;i++){
21 try{
22 Message msg = topics.get(topic).read(offset);
23 messages.add(msg);
24 offset++;
25 } catch (Exception e) {
26 break;
27 }
28 }
29 return messages;
30 }
31}Dont get overwhelmed by those exceptions, I made my own custom exceptions for this project. After the broker abstraction being introduced we removed our Producer and Consumer classes from using Partition object directly and started using Broker object directly.
With broker layer implementation topics also come inside the picture. A topic is a logical abstraction composed of one or more partitions. The broker maintains in-memory metadata mapping topics to partitions. The map currently models each topic as a single partition (simplified from real Kafka, where topics have multiple partitions). And this was all in my initial implementation.
Enhanced my initial Implementation
Till now the flow was like this - 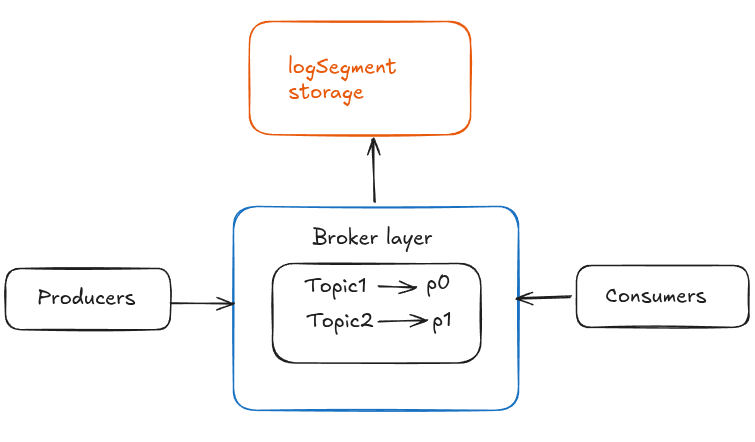
This was the initial flow of my Kafka implementation. Initially there was no broker abstraction, later I introduced a broker layer as shown.
Now as you can see in the above diagram there is only one partition per topic. But in real Kafka there are multiple partitions per topic. So next i started with implementing multi-partition topics.
To implement multi-partition topics i had to introduce and modify various things like
-
tracking of multi-Partitions per topic,
private Map<String, List<Partition>> topics = new HashMap<>(); -
tracking of next-partition index to iterate over
private Map<String, Integer> nextPartitionIndex = new HashMap<>(); -
implemented round-robin for producers to write up the messages in partitions.
1 List<Partition> partitionsList = topics.get(topicName);
2 int idx = nextPartitionIndex.get(topicName);
3
4 Partition partition = partitionsList.get(idx);
5 partition.append(message);
6
7 int nextidx = (idx+1) % partitionsList.size();
8 nextPartitionIndex.put(topicName, nextidx);How this round-robin works?
1
2topics - orders (order topic has 3 partition only and this is how producer writes up in round-robin manner)
3
4orders:
5p0 <- msg1
6p1 <- msg2
7p2 <- msg3
8p0 <- msg4
9p1 <- msg5
10p2 <- msg6 ...Now as we implemented multi-partition topics, i needed to modify consumer to consume messages from all partitions using offsets. And before this if you remember our broker class was calling the consume method of a single partition only. But in Kafka, the broker is stateless in terms of consumption (it does not track consumer offsets), so this was the right time to remove that dependency as multi-partition topics are implemented.
I modified the consumer class by adding offsets per partition to read up the messages sequentially from each partition.
-
tracking of partition list for each topic
private List<Partition> partitionList; -
tracking of offsets per partition to fetch messages sequentially
private Map<Partition,Long> partitionoffset = new HashMap<>(); -
modified poll method to consume messages from all partitions
1 public void poll(int maxMessages) throws Exception{
2 for(Partition p :partitionList){
3 long curroffset = partitionoffset.get(p);
4 for(int i=0;i<maxMessages;i++){
5 try {
6 Message msg = p.read(curroffset);
7 if (msg == null) break;
8 System.out.println("Consumed: " + "Partition" + p + "Offset" + curroffset + "->" + new String(msg.payload));
9 curroffset++;
10 } catch (Exception e) {
11 break;
12 }
13 }
14 partitionoffset.put(p,curroffset);
15 }
16 }Now after this i started implementing consumer groups. I thought the flow is working pretty smoothly but after consumer-groups being implemented i had to modify a lot of things in my core logSegment storage engine. This is what i was talking about earlier — how skipping things like batches, CRC, recovery made things harder later when system started becoming more complex.
- Core logSegment storage
- Partition abstraction over logSegment
- Producer Consumer using up Partition abstraction
- Later up added Broker layer abstraction.
- Added multi-partition topics
- Modified both producer and consumer class according to multi-partition topics.
And after this i started working on consumer groups.
1public class ConsumerGroup {
2 private String groupId;
3 private List<Consumer> consumersList;
4 private Map<Partition, Consumer> partitionAssignment;
5 public ConsumerGroup(String groupId, List<Consumer> consumersList, Map<Partition, Consumer> partitionAssignment){
6 this.groupId = groupId;
7 this.consumersList = consumersList;
8 this.partitionAssignment = (partitionAssignment != null )? new HashMap<>(partitionAssignment) : new HashMap<>();
9 }
10 public void setPartitionAssignment(List<Partition> partitionList){
11 if(consumersList == null || consumersList.isEmpty()){
12 throw new IllegalStateException("No consumers in the group");
13 }
14 if(partitionList == null){
15 partitionList = new ArrayList<>();
16 }
17 for(Consumer c : consumersList){
18 c.clearAssignments();
19 }
20 partitionAssignment.clear();
21 int i = 0;
22 for(Partition p:partitionList){
23 Consumer c = consumersList.get(i % consumersList.size());
24 partitionAssignment.put(p,c);
25 c.addPartition(p);
26 i++;
27 }
28 for (Map.Entry<Partition, Consumer> entry : partitionAssignment.entrySet()) {
29 System.out.println("Assigned: " + entry.getKey() + " -> Consumer " + consumersList.indexOf(entry.getValue()));
30 }
31 }
32}What this ConsumerGroup class is doing?
- it represents a group of consumers working together on the same topic.
- instead of every consumer reading everything, partitions are divided between consumers.
- partition assignment
partitions are distributed across consumers using round-robin so each partition is owned by exactly one consumer at a time. - clearing previous assignments
before assigning again, all consumers clear their old partitions this is similar to rebalancing in Kafka. - round-robin assignment logic
partitions are assigned like:
1 consumers = [c0, c1]
2
3 partitions:
4 p0 -> c0
5 p1 -> c1
6 p2 -> c0
7 p3 -> c1so load is evenly distributed.
- consumer owns partitions
once assigned, consumer will only poll from its assigned partitions this avoids duplicate consumption. - in-memory coordination
all this assignment is happening in-memory there is no distributed coordinator or persistence yet. - simplification compared to real Kafka
no rebalancing triggers (join/leave/heartbeat)
no distributed group coordinator
no offset commit storage in broker.
Real Implementation Starts from here
What i meant by real implementation is that whatever complex thing i left initially just to sart out with a simple implementation, i started implementing them now.
Back to core logSegment storage
Things i have improved/added later on
- Sparse index files implementation
- Records
- Batches
- CRC checksum
- Recovery
Sparse index file implementation
First of all let's understand what is sparse index files?
Earlier reads looked like this partition.read(offset) which was very inefficient. If the file is big this read becomes very slow. And the solution to this is Sparse Index Files.
In this phase i created 1 extra files which was index file in logSegment class. Initially there was only log file in logSegment class responsible to store messages in .log files.
Now there are 2 files
- .log- stores actual messages
- .index - stores sparse index of messages.
Also one thing to highlight which i should have done before is that my implementation has One LogSegment per Partition right now. Later on i added multiple logSegments per partition which we will discuss soon in upcoming section. So my storage flow looked like this after adding up sparse index files.
1 Partition
2 └── ONE LogSegment (single file)
3 ├── .log (actual data)
4 └── .idx (sparse index)To be put in lame java terms, Partition Class till now was using single LogSegment object which had only 1 file. And after adding sparse file index, now LogSegment class stores 2 files as seen above.
Now Let's look up how would an index file look like visually.
lets assume these are my messages of any topic(order topic)
1 msg1 = "order created"
2 msg2 = "order paid"
3 msg3 = "order shipped"
4 msg4 = "order delivered"
5 msg5 = "order returned"
6 msg6 = "order refunded"
7 msg7 = "order closed"
8 msg8 = "order archived"Each messages are stored like this in .log file
[length][offset][timestamp][payload]
and lets assume each messages has length of 50 bytes (avg assumption). Now the log file with bytes length would look like this-
1 Position (bytes) → Data
2
3 [0] offset=1 → "order created"
4 [50] offset=2 → "order paid"
5 [100] offset=3 → "order shipped"
6 [150] offset=4 → "order delivered"
7 [200] offset=5 → "order returned"
8 [250] offset=6 → "order refunded"
9 [300] offset=7 → "order closed"
10 [350] offset=8 → "order archived"And we have set a rule that we will create an index entry for every 3rd message. So we will create index entry for offset 1, 4, 7.
So our index file would look like this-
1Index File (.idx)
2 Offset → FilePosition
3
4 1 → 0 (offset1 starts at 0th position)
5 4 → 150 (offset4 starts at 150th position)
6 7 → 300 (offset7 starts at 300th position)Now lets assume consumer wants offset8, the sparse index file will help to find the closest smaller offset which is 7 and its position 300. Internally it would look like this - file.seek(300); . And it will start reading sequentially from that position and check each message’s offset until it finds offset8.
This was about sparse index files. How i implemented or modified the code that you can check in github and in code file im sure you will understand it better now that you have got an idea how it works.
Also as i mentioned at the start of the blog that i have realised few gaps in my written article after implementing it. This sparse index file was one of the confusion i had and i mixed it up with Segment level index which the paper includes.
Record, Record Batch and CRC checksum implementation
Nothing just Record is a fancy term for messages. Now the next implementation is Record batches. Record Batches is nothing but bunch of records, in distributed systems we usually dont handle individual record appends one by one thats inefficient. Instead we append in Batches, read in Batches and so on.
1 public class RecordBatch {
2 private long baseOffset;
3 private List<Record> recordList;
4 private long crc;
5
6 public RecordBatch(long baseOffset, List<Record> recordList){
7 this.baseOffset = baseOffset;
8 this.recordList = recordList;
9 this.crc = calculateCrc();
10 }
11
12 private long calculateCrc(){
13 CRC32 crc32 = new CRC32();
14 for(Record record : recordList){
15 crc32.update(record.toBytes());
16 }
17 return crc32.getValue();
18 }
19 public boolean isValid(){
20 return calculateCrc() == this.crc;
21 }
22 public List<Record> getRecords(){
23 return recordList;
24 }
25 public long getBaseOffset() {
26 return baseOffset;
27 }
28 public long getCrc() {
29 return crc;
30 }
31 }RecordBatch class is wrapping up a list of records with base offsetsto store and retrieve multiple messages as batches/ a single unit, making reads and writes more efficient in logSegment. Added a CRC as well to ensure data integrity in logSegment storage just to avoid the lost or altered messages.
CRC (Cyclic Redundancy Check) is a mathematical algorithm that generates a fixed size hash based on data's contents. You can read about this more in depth on web. I have used up java's internal CRC methods from their util package.
Now that we have added Record Batches, the system should also support Record Batches append and read.
1 public long append(String message) throws IOException {
2 Record record = new Record(-1, System.currentTimeMillis(), message.getBytes(StandardCharsets.UTF_8));
3 RecordBatch batch = new RecordBatch(-1, List.of(record));
4 return append(batch);
5 }
6 public Record read(long offset) throws Exception {
7 return segment.readByOffset(offset);
8 }Api layer
As we implemented Record, Record Batches, CRC, Batch appends and Batch reads, now we need to expose these functionalities to the outside world. So i created a simple Api layer on top of Partition class.
The producer layer had 2 apis -
- ProduceRequest(topic, partition, messages[])
- ProduceResponse(baseOffset, lastOffset)
The Consumer layer had 2 apis -
- FetchResponse(list<records>,latestoffsets)
- FetchRequest(topic, partition, offset, limit, maxwait)
The Broker layer had 2 apis -
- ListOffsetRequest(topic, partition, OffsetSpec<Earliest/Latest>)
- ListOffsetResponse(offset)
As the above api methods are introduced i made few changes in my logSegment storage class again to support these apis. Added methods like -
- readFromOffsets(offset, limit)
- getLatestOffset()
- getEarliestOffset()
Made more changes in my Producer as well as Consumer classes to support these apis. It provided a good layer of abstraction and separation of concerns. Also if the api things is discussed here i wanna mention this as well that my implementation doesnt have networking part. I could have added it but i didnt want to overcomplicate the code and i left it for future implementations/improvements.
Multiple-Segments per Partition
If you remember in the above sparse index file section, i talked about how my implementation only supported single logSegment per partition that time. So now i added or implemented multiple-Segment per partition. The visualisation might look like this -
1 Partition
2 ├── LogSegment (baseOffset = 0)
3 │ ├── 00000000000000000000.log
4 │ └── 00000000000000000000.idx
5 │
6 ├── LogSegment (baseOffset = 100)
7 │ ├── 00000000000000000100.log
8 │ └── 00000000000000000100.idx
9 │
10 └── LogSegment (baseOffset = 200)
11 ├── 00000000000000000200.log
12 └── 00000000000000000200.idxEarlier everything was going into a single log file, but that is not scalable. So instead of one big file, the log is now split into multiple smaller segments.
What changed in implementation?
- each segment now has a baseOffset
this represents the starting offset of that segment - segment files are named using baseOffset
so each segment is uniquely identified and sorted - each segment still has its own
- .log file (actual data)
- .idx file (sparse index)
Segment Roll(how new Segments are created)
Instead of writing everything to one file, a segment is rolled when certain conditions are met.
In my implementation, a new segment is created when either of the following conditions are met:
-
size-based roll
shouldRollBySize(maxSegmentBytes)
when current segment size reaches a threshold → create a new segment -
time-based roll
shouldRollByAge(maxSegmentAgeMs, now)
when segment becomes too old → create a new segment
When a roll happens -
- current segment is closed
- new segment is created
- its baseOffset = next incoming message offset
Why segment rolling is important?
- avoids very large files
- makes reads faster
- allows deletion of old data easily
- helps in retention management
Retention (deleting old segments)
Now that we have multiple segments, we can delete old data at segment level.
isExpiredForRetention(retentionMs, now) checks if a segment is expired based on retention time.
If a segment is older than retention time:
- entire segment is deleted (.log + .idx)
- no more reads/writes for that segment
Earlier the system behaved like this -
Partition → single LogSegment
Now it behaves like this -
Partition → multiple LogSegments (ordered by baseOffset)
So when consumer reads up it goes like this -
- first find the correct segment based on offset
- then use sparse index inside that segment
- then scan forward in that segment to find the exact offset
- if offset not found in that segment, move to next segment.
The whole consumer read and search will look up like this -
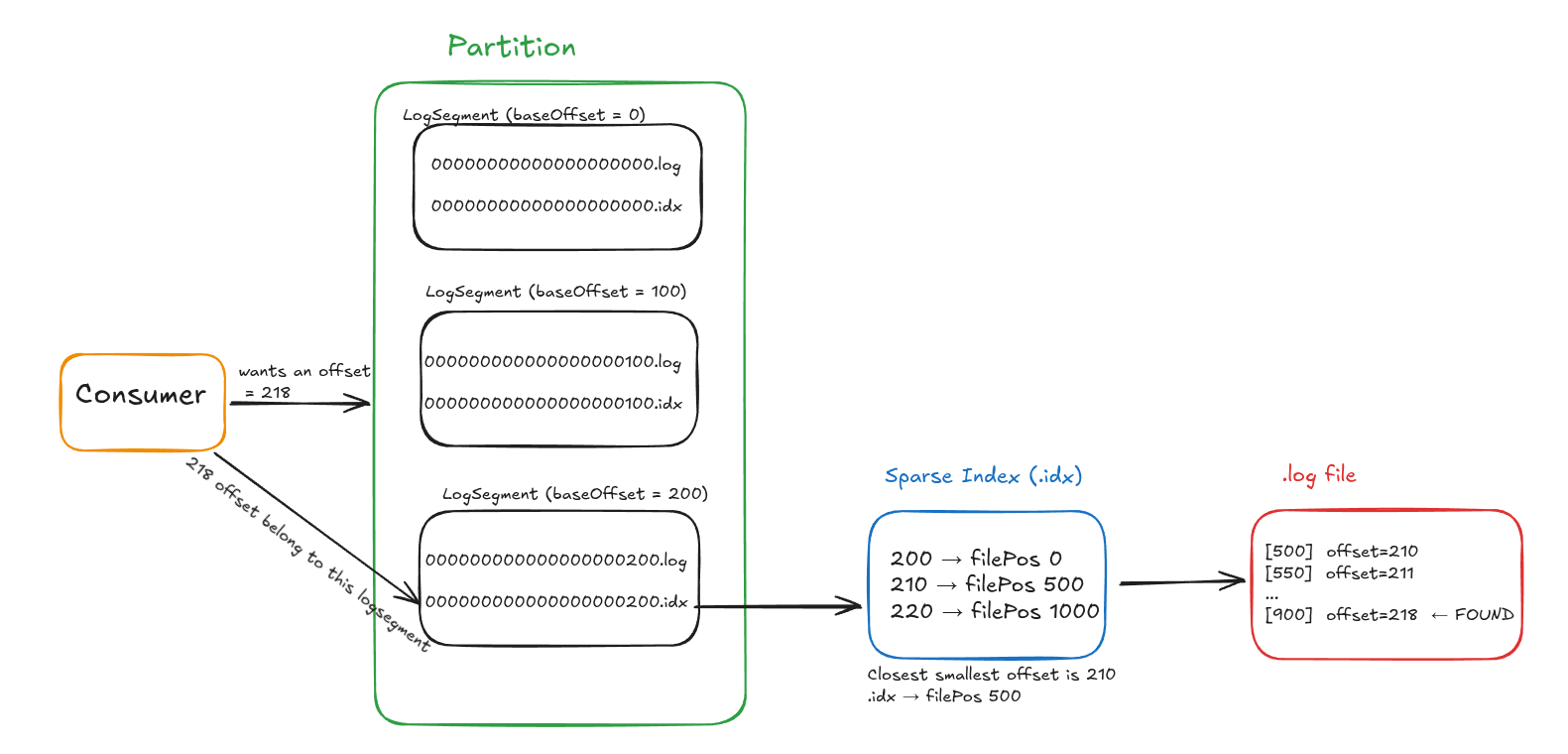 Consumer Read and Search Flow
Consumer Read and Search Flow
Coordination Service (Consumer Groups)
Till now consumers were directly reading from partitions and managing their own offsets. But once consumer groups come into picture, things get a bit more complex.
Now we need something that can:
- track which consumers are part of a group.
- assign partitions to consumers.
- handle rebalancing when consumers join/leave.
- track offsets per partition.
In the Kafka paper, this responsibility was handled using ZooKeeper. Kafka used ZooKeeper for managing group membership, partition ownership and metadata.
In my implementation, instead of using an external system like ZooKeeper, i built a simplified in-memory coordination service to handle all of this.
What this CoordService is doing?
At a high level, this acts like a group coordinator.
Each consumer group has its own state:
- GroupState
- topic → which topic this group is consuming
- partitionCount → total partitions
- generation → version of group (important for rebalances)
- members → active consumers in the group
- assignments → which partition is assigned to which consumer
- ownershipRegistry → which consumer currently owns a partition
- offsetRegistry → last committed offsets per partition
When a consumer joins
joinConsumer(...)
- adds the consumer to the group
- sets topic + partition count
- updates heartbeat info
- triggers a rebalance
Rebalancing (core logic)
rebalance(state)
Whenever:
- a new consumer joins
- a consumer leaves
- a consumer times out
partitions are reassigned again
1 members = [c0, c1, c2]
2 partitions = [0,1,2,3,4,5]
3
4 c0 → [0,1]
5 c1 → [2,3]
6 c2 → [4,5]partitions are evenly distribued
each partition goes to only one consumer
Also
- generation is incremented
- old assignments are cleared
- ownership is adjusted
Heartbeats (keeping consumers alive)
heartbeat(...) Each consumer periodically sends heartbeat.
If heartbeat is not received within: sessionTimeoutMs consumer is considered dead.
Expiring consumers expireTimedOutMembers(...)
- removes dead consumers
- triggers rebalance again
this is how system self-recovers
Partition ownership
This part was something i didn’t think about initially but becomes really important once multiple consumers are involved. At first it might feel like assignment = ownership, but that’s not actually the case.
- assignment → means “you are supposed to read this partition”
- ownership → means “you are currently reading this partition”
Why do we even need ownership?
After a rebalance happens:
- partitions get assigned to consumers
- but that doesn’t mean they immediately start consuming
There can be situations like:
- previous consumer was reading it
- new consumer got assigned but hasn’t started yet
- two consumers trying to read same partition
So instead of directly trusting assignment, i added an ownership layer.
Claiming a partition
claimPartition(...) Before a consumer starts reading a partition, it has to claim it. This will only succeed if :
- the partition is actually assigned to that consumer
- the generation is correct (i.e not stale after rebalance)
- no other consumer is currently owning it
Only after claiming, consumer can actually start reading.
Releasing a partition
releasePartition(...) Once consumer is done (or maybe rebalance happens), it releases the partition. So this basically means i am no longer reading this partition, someone else can take it.
What happens during rebalance? This is important :
- assignments are recalculated.
- but ownership is not blindly kept.
ownership is only kept if that partition is still assigned to same consumer otherwise ownership is removed.
Offset Management
commitOffset(...) consumer commits offset for a partition
only allowed if consumer owns that partition, generation is valid.
readCommittedOffset(...) returns last commited offset, used when consumer restarts.
Multi-Broker Cluster
Till now everything was working on a single broker setup. Even though we had partitions and consumer groups, everything was still happening inside one process.
To move a bit closer to how Kafka actually works, i extended this to support multiple brokers.
Now instead of a single broker owning all partitions, partitions are distributed across multiple brokers.
What needed to be added?
To make this work, i introduced a Cluster Coordination Service which is responsible for:
- tracking active brokers in the cluster
- assigning partitions of a topic to different brokers
- routing requests to the correct broker
Broker Registration
Each broker first registers itself:
registerBroker(...)
- brokerId → unique id of broker
- endpoint → where it is running
- sessionTimeoutMs → used to detect failure
After registration, brokers send periodic heartbeats:
brokerheartbeat(...) This keeps them marked as alive.
Handling Broker Failures
expireTimedOutBrokers(...)
- if a broker stops sending heartbeats
- it is considered dead and removed from cluster
This is a very simplified failure detection mechanism.
Topic Partition Placement
createTopicStaticPlacement(...) When a topic is created:
- all active brokers are fetched
- partitions are distributed across brokers
1 brokers = [0,1,2]
2 partitions = [0,1,2,3,4,5]
3
4 p0 → broker0
5 p1 → broker1
6 p2 → broker2
7 p3 → broker0
8 p4 → broker1
9 p5 → broker2This is simple round-robin placement across brokers. Each partition is owned by exactly one broker.
Routing Requests
Whenever a producer or consumer wants to interact with a partition: ownerBroker(topic, partition)
- returns which broker owns that partition
- request is routed to that broker
So now flow becomes:
Producer → ClusterCoordService → correct Broker → Partition → LogSegment
Cluster Metadata
metadataSnapshot()
- returns list of alive brokers
- returns partition → broker mapping
This is similar to how Kafka clients fetch metadata before sending requests.
What this implementation does
-
supports multiple brokers
-
distributes partitions across brokers
-
routes requests correctly
-
handles basic broker failure detection
What is still missing (compared to real Kafka)
- no replication across brokers
- no leader/follower model
- no automatic rebalancing after broker failure
- no distributed consensus
So this is not a fully distributed Kafka cluster yet, but a simplified multi-broker setup.
Closing
This was the final layer of my implementation where the system moved from a single-broker setup to a multi-broker cluster-like architecture. After completing this, i tested the entire system with different scenarios and wrote some basic benchmarks as well. You can check those along with the full implementation details in my GitHub README.